In this article, we will see how to delete duplicate rows from a table and keep only one using various ways, mainly:
- Delete the duplicate rows but keep latest : using GROUP BY and MAX
- Delete the duplicate rows but keep latest : using JOINS
- Delete the duplicate row but keep oldest : using JOINS
- Delete the duplicate row but keep oldest : using ROW_NUMBER()
We will start by preparing the data. We will be creating a table sales_team_emails and inserting the data into it.
#CREATE THE TABLE
CREATE TABLE sales_team_emails (
sales_person_id INT AUTO_INCREMENT,
sales_person_name VARCHAR(255),
sales_person_email VARCHAR(255),
PRIMARY KEY (sales_person_id)
);
#INSERT THE DATA
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Aditi","[email protected]");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Furan T","[email protected]");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Veronica Hedge","[email protected]");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Atharv","[email protected]");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Erick","[email protected]","45 Parking West London");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Rasmus","[email protected]");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Aditi Sharma","[email protected]");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Furan T","[email protected]");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Veronica Longman","[email protected]");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Simon Rappid","[email protected]");
INSERT INTO sales_team_emails (sales_person_name,sales_person_email)
VALUES("Simon Rappid","[email protected]");
Through the table, let us see by doing select * and keeping the rows ordered by sales_person_email.
SELECT * FROM sales_team_emails ORDER BY sales_person_email;
Output:-
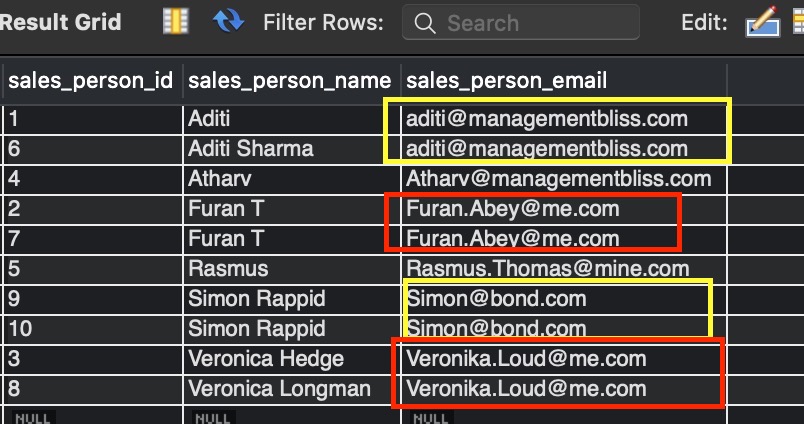
The output shows that the table sales_team_emails contains duplicate values in the column sales_person_email.
Know more about How to Find Duplicate Rows in MySQL.
Delete the duplicate rows but keep latest : using GROUP BY and MAX
One way to delete the duplicate rows but retaining the latest ones is by using MAX() function and GROUP BY clause. Observe the below query and output.
DELETE FROM sales_team_emails
WHERE sales_person_id NOT IN (
SELECT * FROM (
SELECT MAX(sales_person_id) FROM sales_team_emails
GROUP BY sales_person_email
) AS s_alias
);
Action Output Message : DELETE FROM sales_team_emails WHERE sales_person_id NOT IN ( SELECT * FROM ( SELECT MAX(sales_person_id) FROM sales_team_emails GROUP BY sales_person_email ) AS s_alias ) 4 row(s) affected 0.0061 sec.
Frequently Asked:
Select * on sales_team_emails table to view the output.
Output :
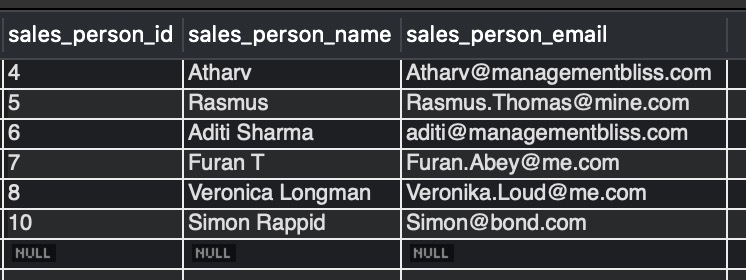
Explanation:- As we can see in this output, we have successfully deleted the duplicate rows. Here we are using the inner query, MAX() function, and GROUP BY clause.
- STEP 1: In the inner query, we are selecting the maximum sales_person_id grouped by the sales_person_email.
- STEP 2: In the outer query, we are deleting from table sales_team_emails all other rows except for those in the inner query (STEP 1).
Delete the duplicate rows but keep latest : using JOINS
Another way to achieve the goal is to use joins to delete the old entries from the table and preserve the latest entry in the table sales_team_emails comparing the sales_person_id column. Observe the below query :
DELETE s1 FROM sales_team_emails s1,
sales_team_emails s2
WHERE
s1.sales_person_id < s2.sales_person_id
AND s1.sales_person_email = s2.sales_person_email;
Action Output Message : DELETE s1 FROM sales_team_emails s1, sales_team_emails s2 WHERE s1.sales_person_id < s2.sales_person_id AND s1.sales_person_email = s2.sales_person_email 4 row(s) affected 0.0053 sec
Select * on sales_team_emails table to view the output.
Output :
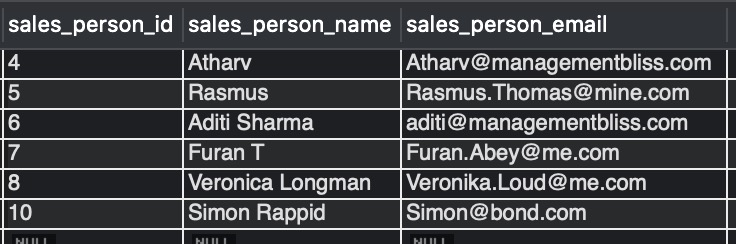
Explanation:- As we can see in this output, we have successfully deleted the duplicate rows, and the ones with higher sales_person_id ( sales_person_id is the primary key) are retained. Here we are doing a self join on the same table sales_team_emails, which is deleting duplicate records by keeping one copy, the one with a higher value of sales_person_id.
Delete the duplicate row but keep oldest : using JOINS
JOINS can be used to keep the oldest entry of duplicate rows but delete the ones who entered late into the table. The solution is similar to the one in the above section with a little change in the WHERE clause. Observe the below query and its output.
DELETE s1 FROM sales_team_emails s1,
sales_team_emails s2
WHERE
s1.sales_person_id > s2.sales_person_id
AND s1.sales_person_email = s2.sales_person_email;
Action Output Message: DELETE s1 FROM sales_team_emails s1, sales_team_emails s2 WHERE s1.sales_person_id > s2.sales_person_id AND s1.sales_person_email = s2.sales_person_email 4 row(s) affected 0.0025 sec
Select * on sales_team_emails table to view the output.
Output:-
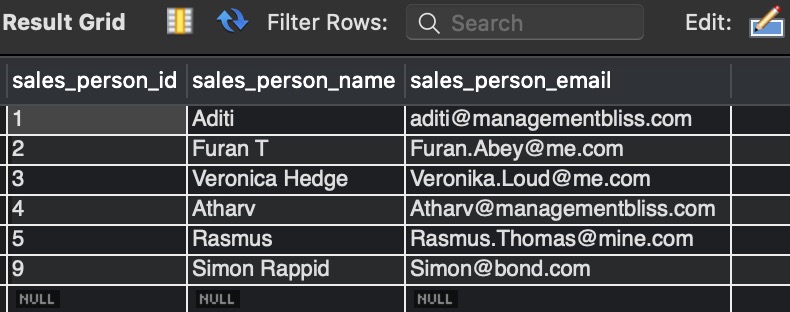
Explanation:- The output shows the oldest rows preserved but the latest duplicate rows deleted. The only change is in the WHERE condition “WHERE s1.sales_person_id > s2.sales_person_id”
Delete the duplicate row but keep oldest : using ROW_NUMBER()
Another approach to delete the duplicate rows retaining the oldest entries in the table is using ROW_NUMBER () function and PARTITION BY clause. Observe the below query, its output, and explanation.
DELETE FROM sales_team_emails
WHERE
sales_person_id IN (
SELECT
sales_person_id
FROM (
SELECT
sales_person_id,
ROW_NUMBER() OVER (
PARTITION BY sales_person_email
ORDER BY sales_person_email) AS row_num
FROM
sales_team_emails
) s_alias
WHERE row_num > 1
);
Action Output Message : DELETE FROM sales_team_emails WHERE sales_person_id IN ( SELECT sales_person_id FROM ( SELECT sales_person_id, ROW_NUMBER() OVER ( PARTITION BY sales_person_email ORDER BY sales_person_email) AS row_num FROM sales_team_emails ) s_alias WHERE row_num > 1 ) 4 row(s) affected 0.0017 sec
Output :-
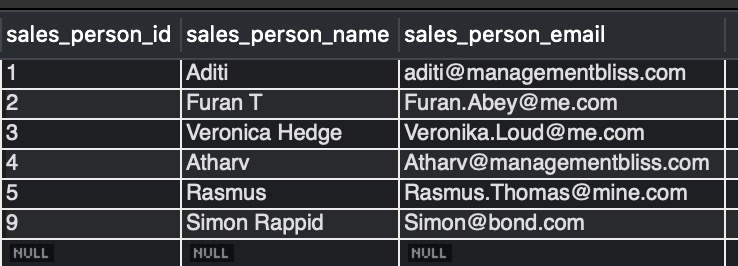
Explanation:- As we can see in the output, the latest duplicate rows got deleted. Here we are using inner queries and ROW_NUMBER() function.
- STEP 1: In the innermost query “SELECT sales_person_id, ROW_NUMBER() OVER (PARTITION BY sales_person_email ORDER BY sales_person_email) AS row_num FROM sales_team_emails“ we are partitioning the entire table into small sections using PARTITION BY clause based on sales_person_email. Then ROW_NUMBER() function assigns the row numbers to each row, creating a separate column row_num. If we run this inner query separately, we get the output:-
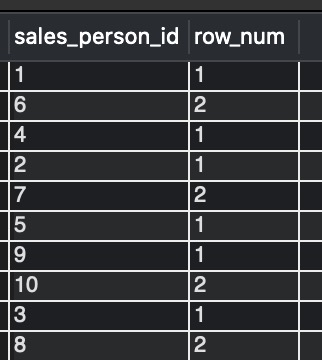
- STEP 2: In the next inner query, we do a select sales_person_id , WHERE row_num > 1 from the innermost query results (STEP 1)- figure 1.6. On running it separately will give the output:-
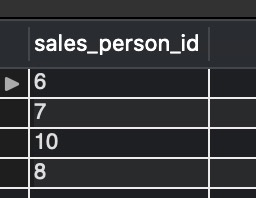
- STEP 3: Finally, do delete in the outer query for all the rows with sales_person_id equal to the ones found in the inner query (STEP 2) – figure 1.7.
We hope this article helped you with deleting the duplicate rows. Good Luck !!.